An intro to Web Scraping in Python.
Tutorial: Getting the Telephone Numbers of Hospitals in the Ashanti Region, Ghana.

I thought a fun way to practise web scraping was to develop a practical tool: a map of hospitals in Ghana with their telephone numbers appended. I got the list of hospitals from: ghanahospitals.org
I thought this would be useful as I have had a few people ask me for the phone numbers of some hospitals. I have learnt to code in both Python and R so I decided to provide code for both languages. This tutorial assumes basic to intermediate level of knowledge in Python/R and html. Let's start with Python.
Python:
First, we open the link and see there's a list (hyperlinks) of hospitals in alphabetical order. Let's select one of the hospitals. Here, with Microsoft Edge as my web browser, I select "Abrafi Memorial Hospital". The page opens and then I highlight the line containing the telephone number, right click and select Inspect so I can locate it in the DevTools Elements tab. The main thing to note here is the div tag under which the telephone number is located, and the associated class name, 'fdtails_home'
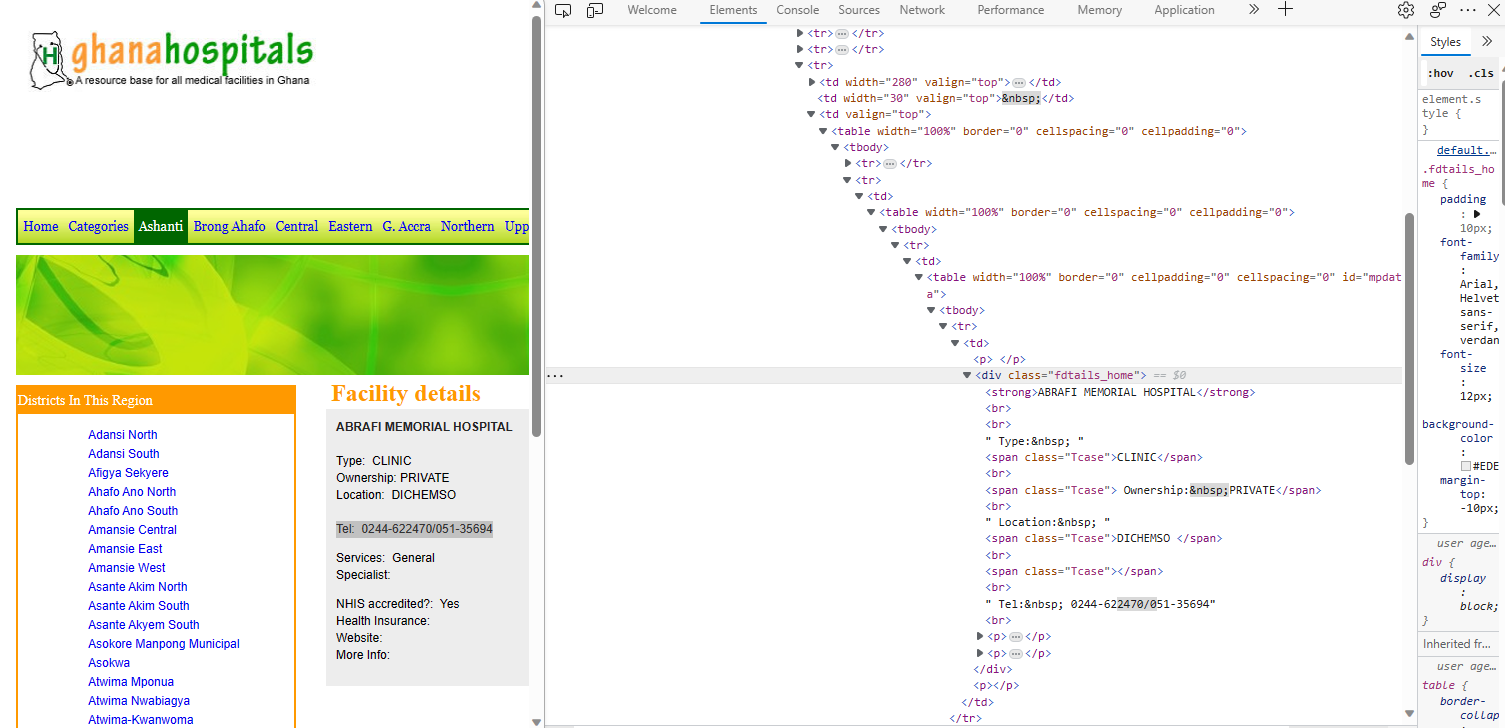
Now let's get into our Python IDE. We will import the required libraries and modules.
import requests #used to interact with web services so you can for example,send HTTP requests
from bs4 import BeautifulSoup #it's a beginner-friendly library for web scraping and data extraction from HTML and XML documents.
import re #for string manipulation
import pandas as pd #for working with structured data
from geopy.geocoders import Nominatim #from the OpenStretMap project, used for geocoding
Next, we send a request to
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.12; rv:55.0) Gecko/20100101 Firefox/55.0',
} #this is an optional argument passed to the get function of the requests module to customize the format of the response received.
website = 'https://ghanahospitals.org/regions/fdetails.php?id=422&r=ashanti' #the site we are scraping from
result = requests.get(website, headers =headers)
content = result.text
soup = BeautifulSoup(content, 'lxml') #the lxml argument is to parse on the html data we get back as a response/
pages_data = soup.select('.fdtails_home')[0].get_text()
This is the output we get when we view 'pages_data':
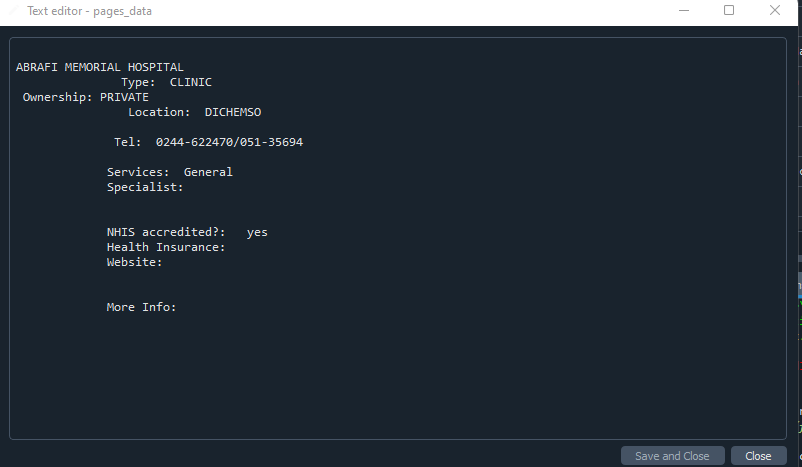
We're almost there. Now, we have to retrieve the telephone number and we can use regular expressions (regex), together with the re module to do this:
pattern = r'Tel:.+'
tel_match = re.search(pattern, pages_data)
print(tel_match)
Mission accomplished! You can use this info in different projects. For me, I wanted to locate these health facilities on a map together with their phone numbers. You can view the end result here: http://bit.ly/ghanahospitalmap
Now to locate this hospital on a map, we need its longitude and latitude and Nominatim will help with that:
geolocator = Nominatim(user_agent="my-app")
location = geolocator.geocode("Abrafi Memorial Hospital, Ashanti Region, Ghana")
print(location.longitude)
print(location.latitude)
And that's it! Of course, to geolocate the entire list of hospitals, I retrieved both the hospital names and telephone numbers with the help of regex, the re module, lists and for loops. You can try and have fun with that now that we have seen how to get the results for one!
Happy Coding!
